Coursera Machine Learning - Week6-1 Advice for Applying Machine Learning
CourseraのMachine Learningについてまとめています。 前回は、Week5 Neural Networks Learningについてまとめました。
Week6の前半のまとめです。ようやく半分まできました。ここでは、機械学習のデバッグ方法等について学びます。
Advice for Applying Machine Learning
下記のコスト関数のLinear regressionを実装し、住宅の価格予測を行ったとします。
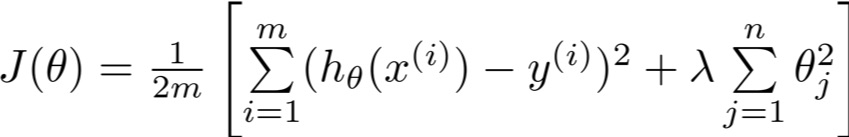
この時に、予測した値が実際の値から大きくずれていた場合、どのように対応すべきでしょうか。例えば、下記のようなオプションがありますが、実際にどのように対応していけば良いのかをここでは学んでいきます。
- トレーニングデータを増やす
- Featureの数を減らす
- Featureの数を増やす
- 多項式のFeature(x12, x22, x1*x2 等)を追加する
- λを小さくする
- λを大きくする
Evaluating a hypothesis
まずは、仮説の評価方法について。評価するにあたり、トレーニングデータの70%をTraining set、30%をTest setとしてデータを分けて利用するのが良いとのことです。30%をテスト用に残しておくことで、70%のデータでトレーニングした結果の仮説がどのくらいの精度なのかを評価することができます。Linear regressionとLogistic regressionのテストエラーは、下記の数式で計算可能です。
Linear regressionテストエラー
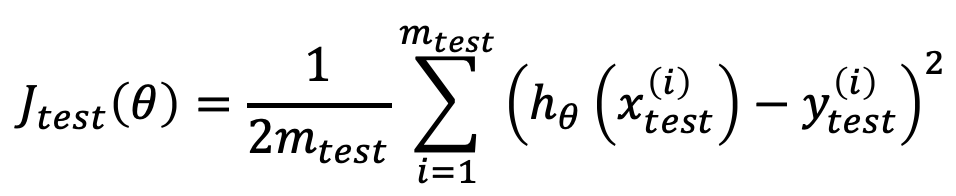
Logistic regressionテストエラー
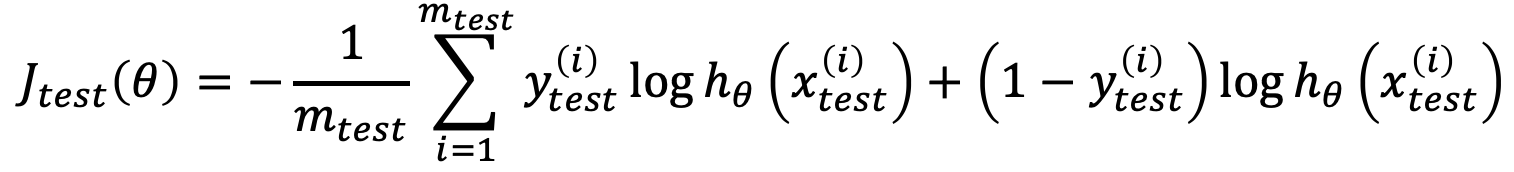
Model selection and training/validation/test sets
何次の多項式のFeatureまで用いるのか、正規化パラメータλをいくつにするのかといった問題は、モデル選択問題と呼ばれています。これを行うために、データをTraining setとTest setの2つではなく、Training set、Cross validation set、Test setの3つに分けます。割合としては、Training set: 60%、Cross validation set: 20%、Test set: 20%くらいにするのが良いそうです。
例えば、何次の多項式のFeatureまで用いるのかを検討する場合、1~10次までのパターンを準備し、それぞれTraining setを用いてトレーニング、その結果をCross validation setを用いて、検証します。検証の際には、上記で記載したテストエラーと同様の数式を用いてコストを算出し、コストが最小となる多項式のパターンを選択します。最後に、そのパターンに対して、Test setを用いて、エラーを検証します。
何次の多項式を選んだかは、Cross validation setを用いてフィッティングしたことになるため、Test setを用いてモデルの汎化誤差を測ることができます。
Diagnosing bias vs. variance
機械学習で、アルゴリズムを走らせていて、期待していたほどの結果が出ていない場合、その問題は、多くの場合、High bias(アンダーフィット)かHigh variance(オーバーフィット)の2つに分けられるそうです。
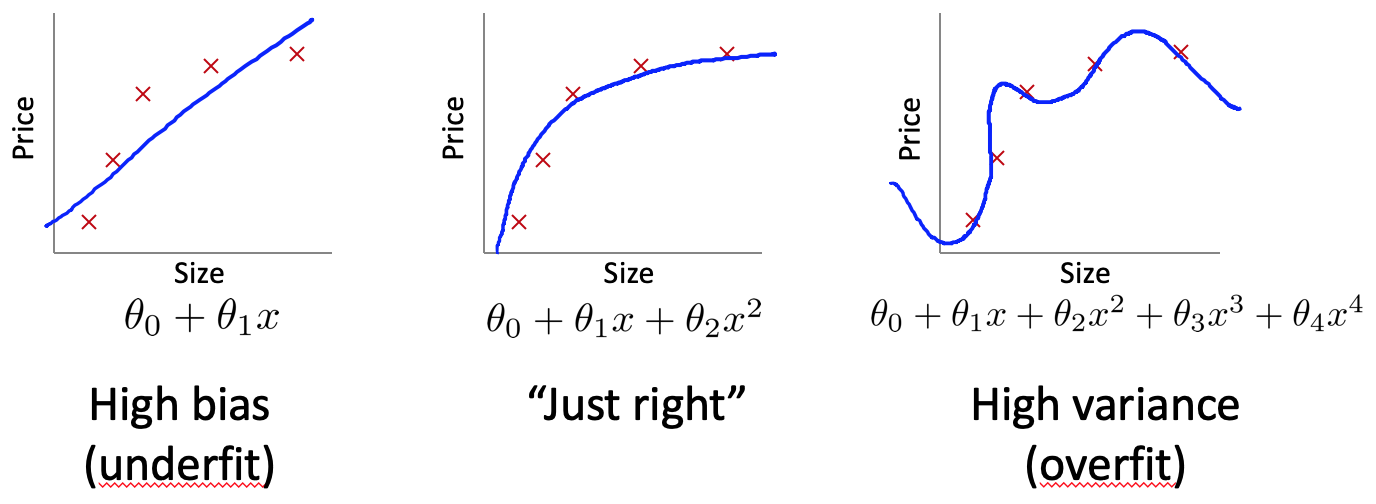
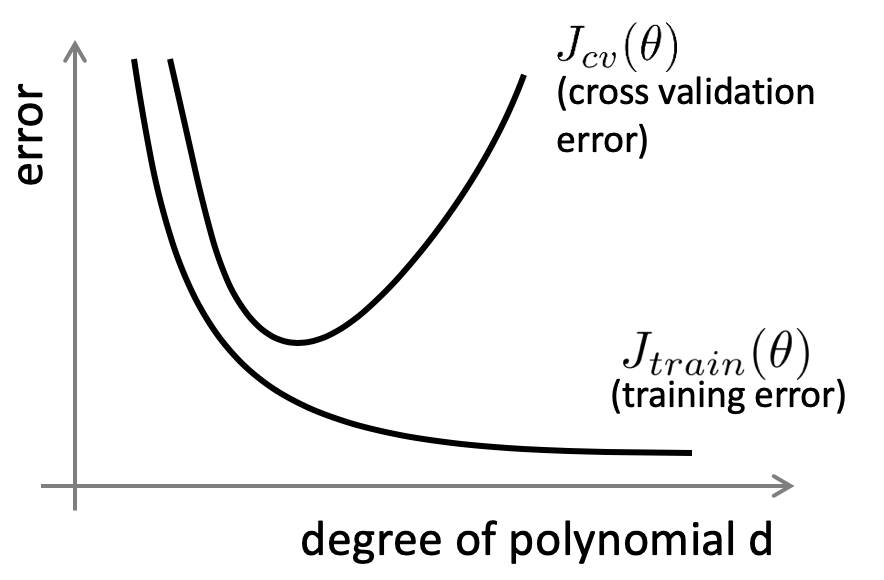
この検証にもCross validation setを用います。先ほどと同じように、何次の多項式のFeatureまで用いるのかを検討する場合、横軸を多項式の次数とし、縦軸をエラーとして、下記のようなグラフを描画します。グラフの左側では、Training errorが高く、Cross validation errorも同様に高くなっています。この場合は、High bias(アンダーフィット)だと考えられます。一方で、グラフの右側では、Training errorが低くなっているが、Cross validation errorが高くなっており、トレーニングデータにフィットさせすぎている、High variance(オーバーフィット)の状態だと考えられます。High biasやHigh varianceにならないよう、Cross validation errorが最小となる次数を選択する必要があります。
Regularization and bias/variance
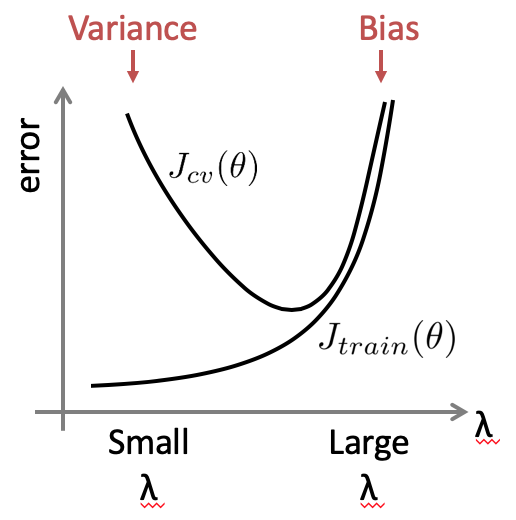
次にRegularization λがどのようにBiasとVarianceに影響を与えるかを学びます。λは、各Featureからの影響が大きくなりすぎないよう、High varianceを抑えるために、各パラメータへのペナルティとして導入しました。
λが大きい場合は、λを考慮しないθ0以外の、θ1以降のパラメータがゼロに近くなるため、θ1=0, θ2=0,,, h=θ0 となり、High biasとなってしまいます。一方で、λが小さい場合は、べナルティが小さいため、High varianceになってしまいます。
グラフにすると下記のようになり、λの選択の際も、Cross validation setを用いて、Cross validation errorが最小となるようなλを選択します。
Learning Curves
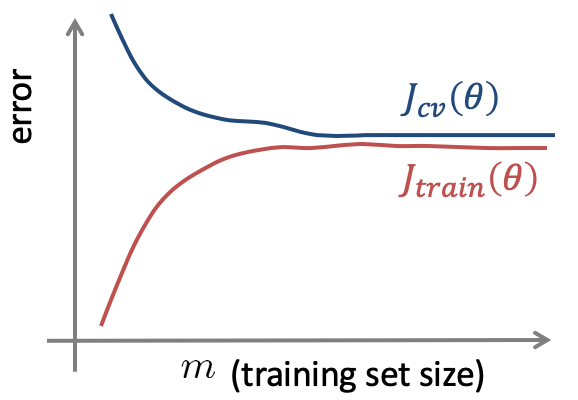
最後に、Learning curves(学習曲線)について学びます。Learning curvesは、アルゴリズムが正しく機能しているかの確認や、アルゴリズムのパフォーマンス改善に役立ちます。Learning curvesをプロットする際は、Training set mを横軸に取りグラフを描きます。
モデルがHigh bias(アンダーフィット)になってしまっている場合は、トレーニングデータを増やしたとしても意味がなく、下記のようなグラフとなります。
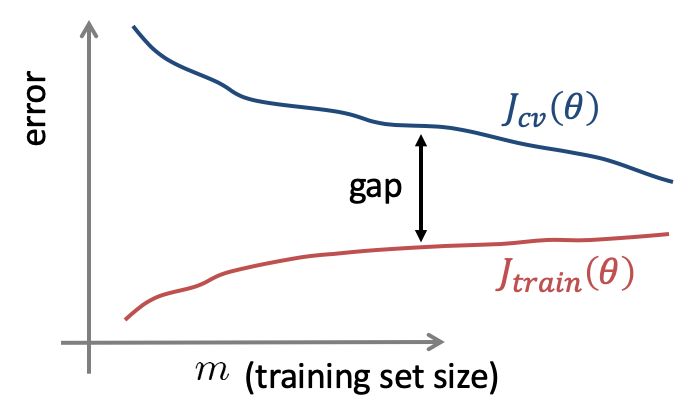
一方で、モデルがHigh variance(オーバーフィット)になってしまっている場合は、トレーニングデータを増やすことに意味があり、Cross validation errorは、トレーニングデータ量に応じて下がっていきます。
Deciding what to try next
最後にまとめです。冒頭で下記のようなオプションを提示しましたが、それらがどのような意味があるのかを整理します。
- トレーニングデータを増やす → High varianceへの対応
- Featureの数を減らす → High varianceへの対応
- Featureの数を増やす → High biasへの対応
- 多項式のFeature(x12, x22, x1*x2 等)を追加する → High biasへの対応
- λを小さくする → High biasへの対応
- λを大きくする → High varianceへの対応
また、Neural Networkのサイズ(Hidden layerの層数とそのUnit数)についても言及があります。
- 小さな Neural Network(Hidden layerの層数が少なく(1層とか)、Unit数が少ない)場合:
- High bias(アンダーフィット)になりやすい
- 必要な計算量が少ない
- 大きなNeural Network(Hidden layerの層数が多く、Unit数が多い)場合:
- High variance(オーバーフィット)になりやすい
- 必要な計算量が多い
- オーバーフィットには、λを用いて対応する
次回は、Week6の後半、Machine Learning System Designで、機械学習システムをどう設計していくかについてまとめます。
コース全体の目次とそのまとめ記事へのリンクは、下記の記事にまとめていますので、参照ください。
Coursera Machine Learningまとめ本記事を読んでいただきありがとうございます。
機械学習を実際に使うにあたり、Coursera MLと合わせておすすめしたい書籍を紹介します。

Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎
scikit-learnを用いた機械学習を学ぶのに最適な本です。

ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
Deep Learningと言えばこれ。TensorFlowやPyTorch等のフレームワークを用いずに、基礎の理論からDeep Learningを実装します。Week4、Week5の記事を読んで、より深く理解したいと思った人におすすめです。

Kaggleで勝つデータ分析の技術
データ分析について学び始めた人におすすめです。