Coursera Machine Learning - Week7 Support Vector Machines
CourseraのMachine Learningについてまとめています。 前回は、Week6の後半、Machine Learning System Designについてまとめました。
Week7では、SVM(Support Vector Machines / サポートベクターマシン)について学びます。
Support Vector Machines
Support Vector Machinesは、複雑な非線形の関数を学習する方法の1つです。
SVMを学ぶにあたり、まずは、Logistic Regression(詳細は、Week3前半のまとめを参照ください)について振り返り、それをベースに、SVMがどのようなものか学んでいきます。
Logistic Regressionでは、Hypothesis hを下記の数式で定義しました。
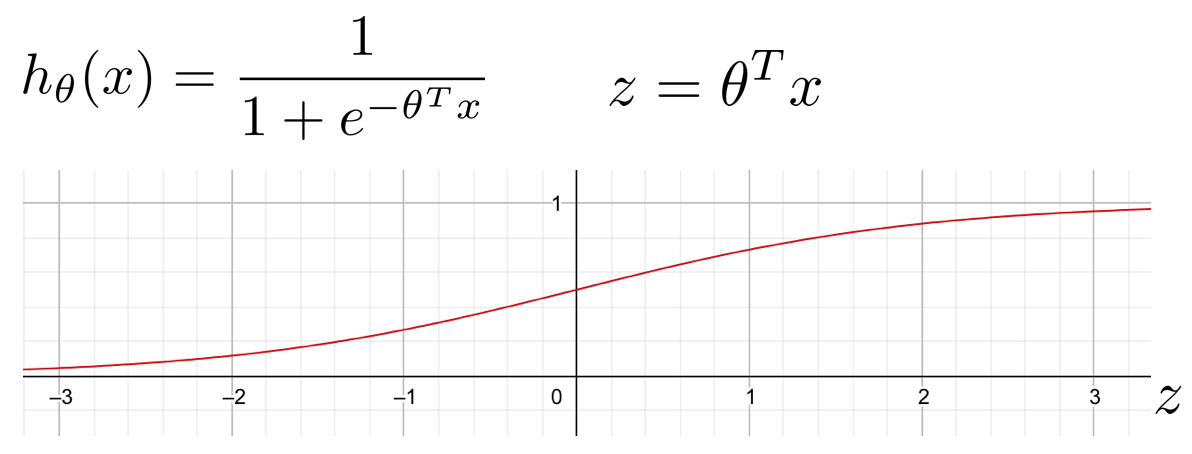
これは、
- y = 1のとき、h ≈ 1と出力したいので、θTx ≫ 0 である必要があり、
- y = 0のとき、h ≈ 0と出力したいので、θTx ≪ 0 である必要がある
ということです。
また、Logistic Regressionでは、コスト関数を下記のように定義し、それぞれの項のグラフは下記のようになっています。
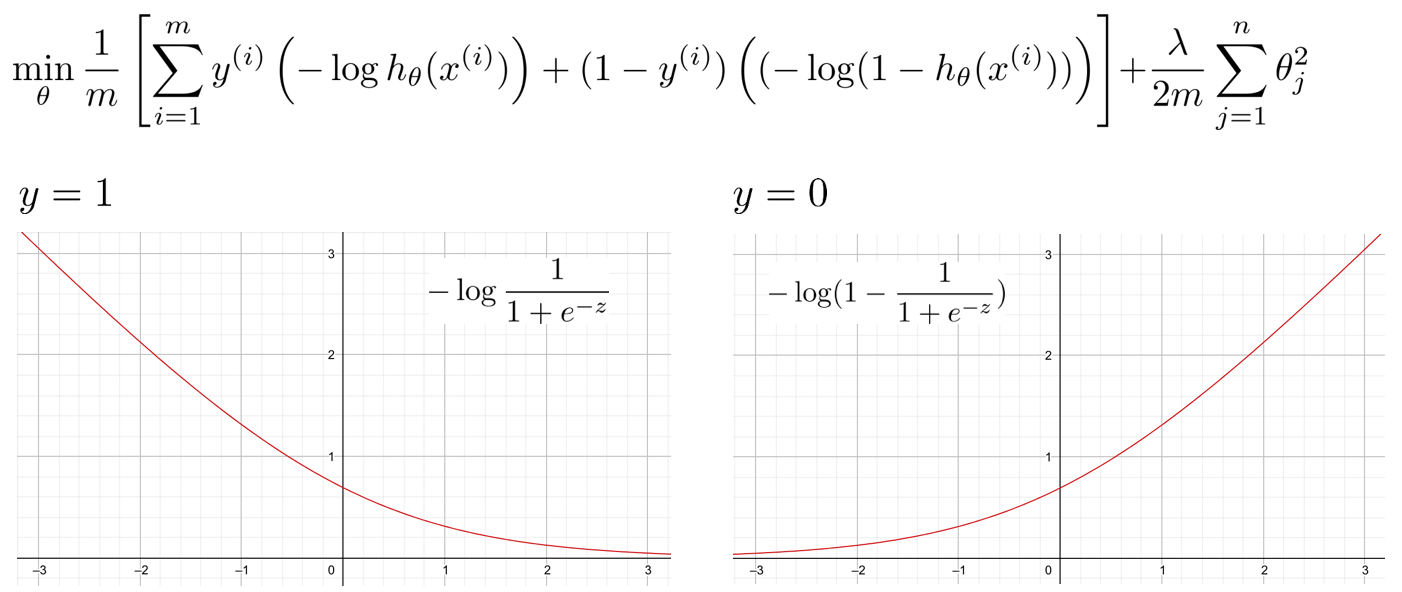
SVMでは、このコスト関数を下記のように変えます。
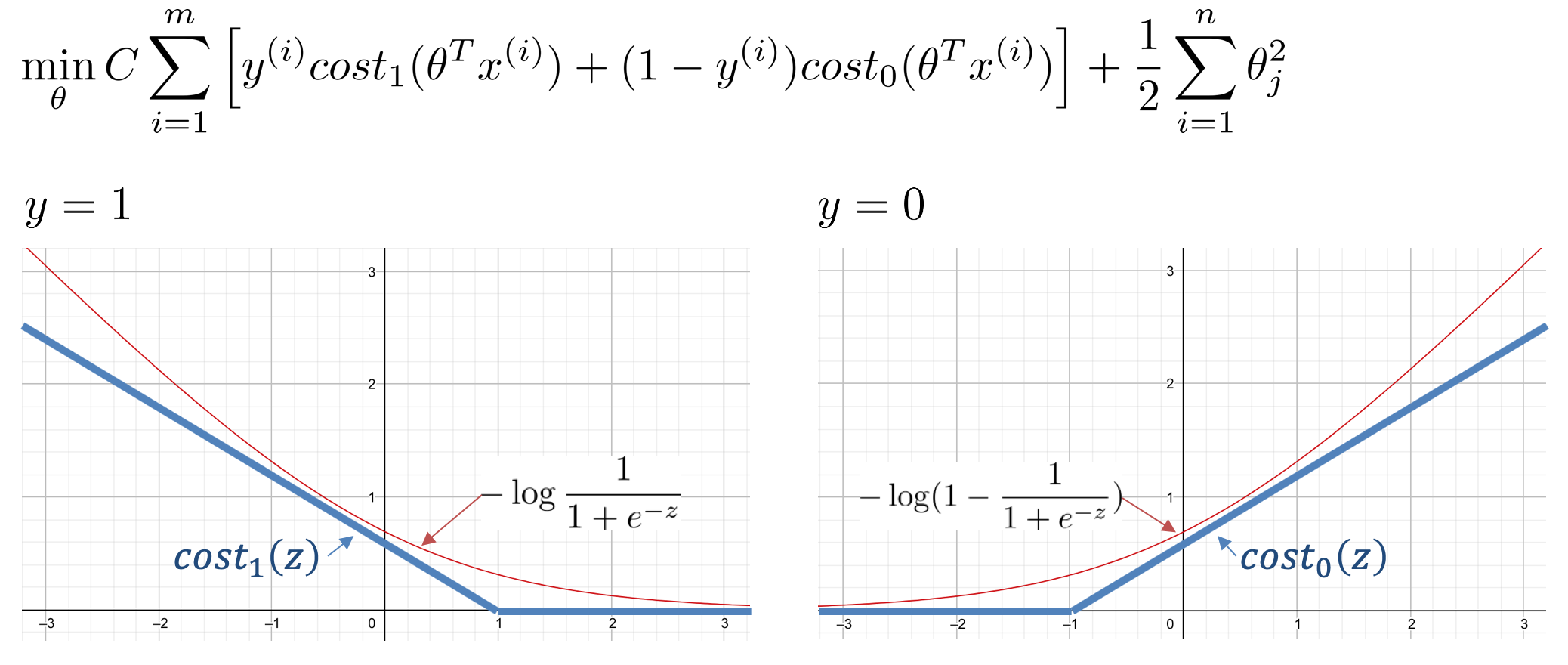
ここで定義したcost1は、z=1以上で0となり、それ以下では、グラフで示したような直線となります。この直線の傾きはあまり関係ないそうです。cost0の場合も同様で、z=-1以下で0となり、それ以上では、グラフで示したような直線となります。
コスト関数に出てくるCは、パラメータで、1/λと同じような役割のものだとみなすことができるそうです。
SVMでは、コストを上記のように定義するため、y=1のときは、zが1以上(cost1=0)となることを求め、y=0のときは、zが-1以下(cost0=0)となることを求めます。hのことを考えると、y=1のとき、zが0よりも少しでも大きければ、h=1と予測するため、zは0よりも少しでも大きければ良いのですが、SVMの場合は、zが1以上となることを要求します。これは、SVMでは、追加のセーフティマージンを組み込んでいると考えることができるそうです。
コスト関数のパラメータCに、100,000等のかなり大きな数字を用いた場合、コストを最小化するために、y=1のときはz≧1、y=0のときはz≦-1を取ろうとし、下記のようにコスト関数の左側の項は0となります。
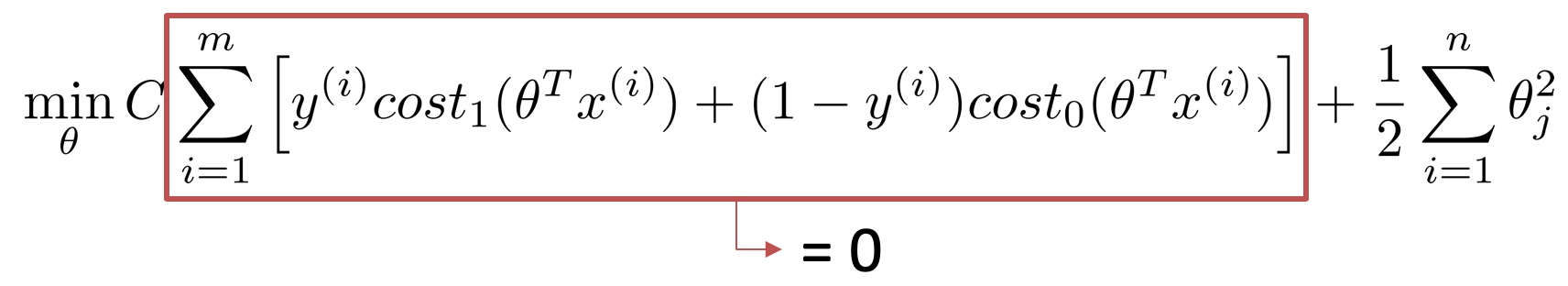
この際に、残る右側の項を最小化しようとすると、いい感じの境界線を得られるそうです。具体的には、下記図の緑やオレンジの境界線ではなく、黒色の境界線を得ることができるそうです。各境界線からサンプルまでの距離は、マージンと呼ばれ、黒色の線の方が緑やオレンジの線よりも大きなマージンを持っています。
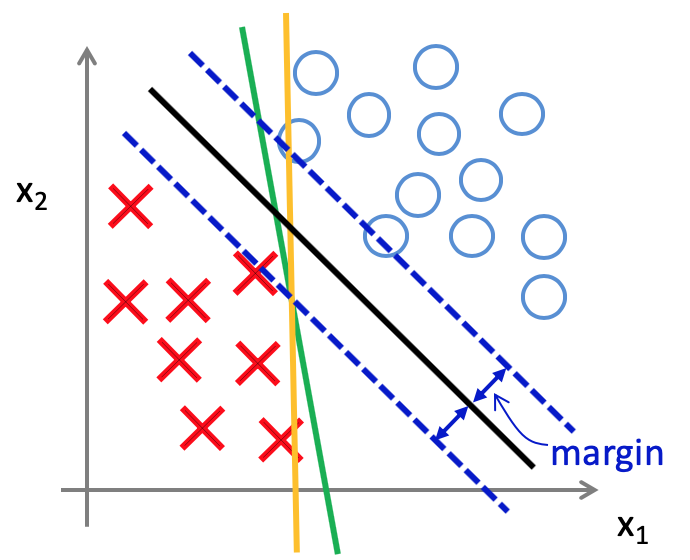
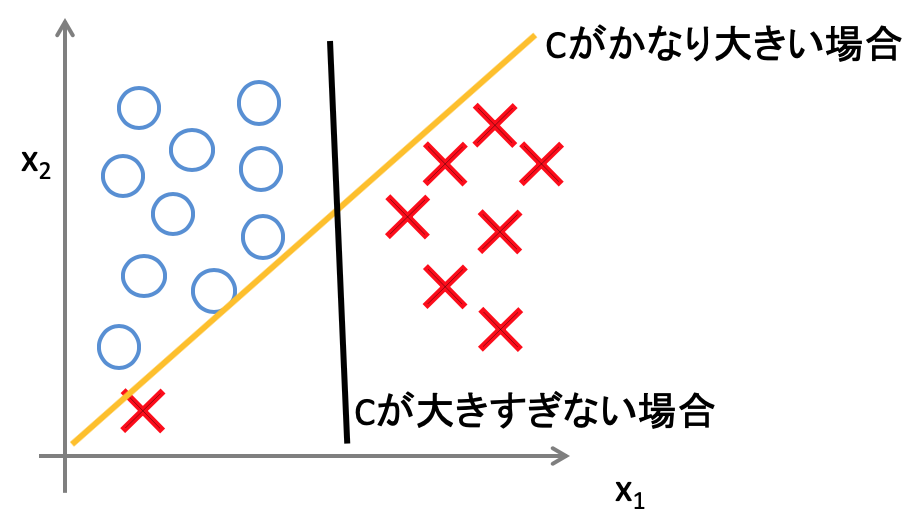
また、パラメータCの値ですが、トレーニングデータには、外れ値も存在する可能性があるため、通常はそこまで大きなものとはしないそうです。Cが大きすぎると、外れ値に敏感になるため、下記のようなデータの分類の際に、オレンジ色の境界線となってしまいます。
SVMでは、どうしてこのように大きなマージンを取る境界線を引くことが出来るのか。Courseraの講義では、その数学的な説明も行なっているので、興味のある人は見てみてください。(すみません、そこまでちゃんと理解して記述できませんでした。。)
Kernels
SVMを用いて、複雑な非線形の分類器を構築するために、Kernels(カーネル)を用います。
下記のようなデータサンプルがあったとして、その境界線を得たいとします。これを行う方法として考えられるのが、下記の黒字で記載しているような多項式のフィーチャーを用いることです。ここで、多項式以外の、青字で記載したような数式の別のフィーチャーを用いることができないかと考えて作られたのがカーネルです。

新しいフィーチャーf1, f2, f3,,,を定義するために、まず、フィーチャーx1, x2の空間に、新たな点l(1), l(2), l(3)を置きます。このlは、ランドマークと呼ばれるそうです。ここで、新たなフィーチャーf1, f2, f3を、xとlのsimilarity関数として定義します。similarity関数は、xとlがどれだけ類似しているかを測る関数です。このsimilarity関数が、Kernel関数で、今回の関数は具体的には、Gaussian Kernels(ガウスカーネル)と呼ばれます。similarity関数には、ガウスカーネル以外にも様々なものがあるそうです。
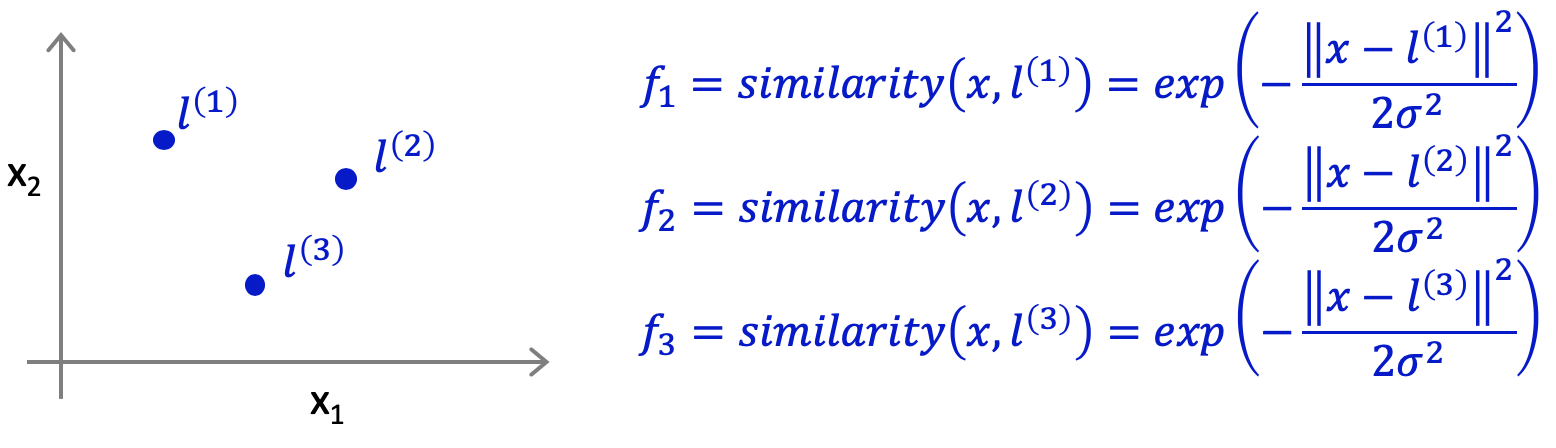
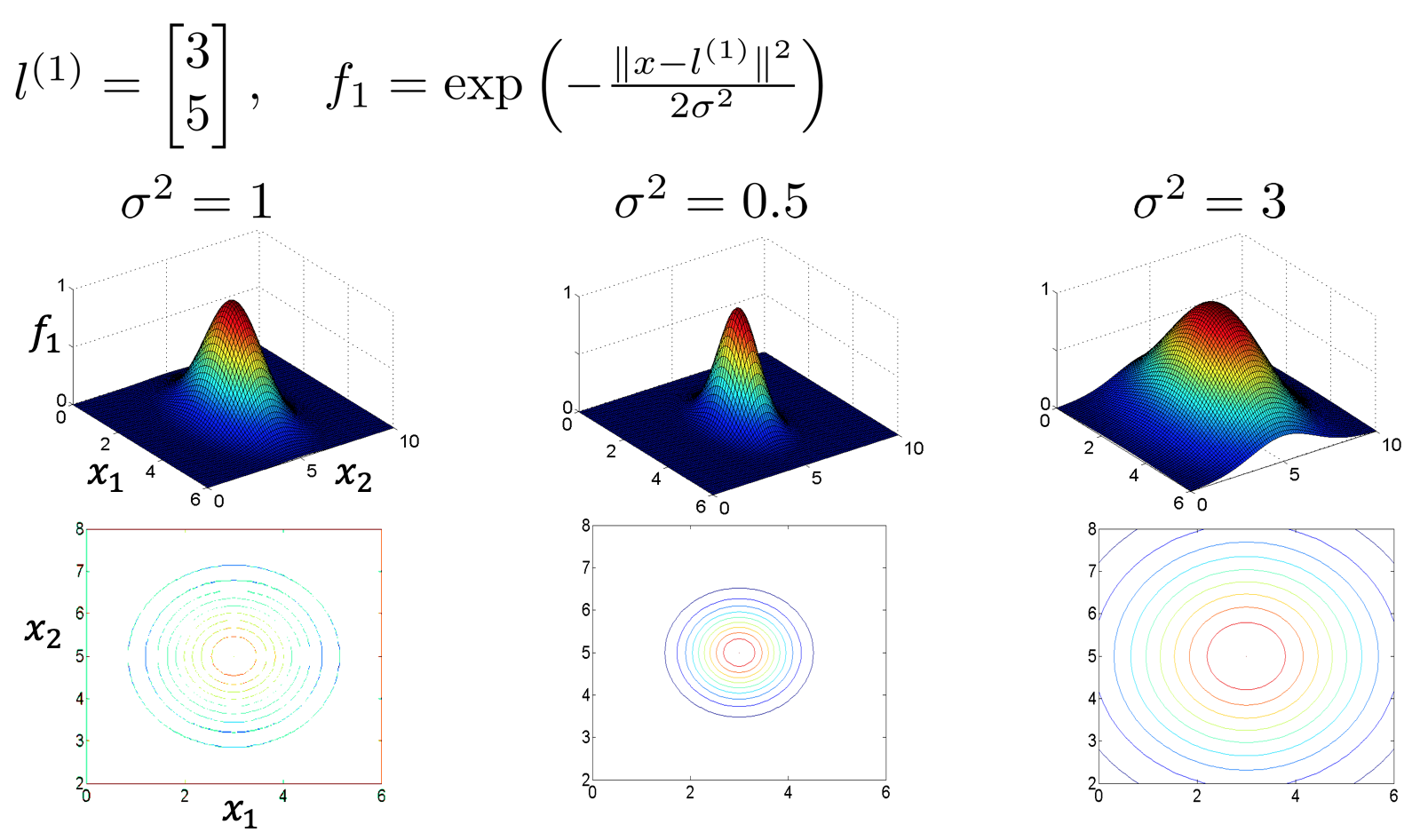
similarity関数についてですが、xとlが近い時は、fの値は1に近くなり、xとlが離れている場合には、fの値は0に近くなります。図示すると下記のようになり、xとlの値が同じ場合に、最大値1を取ることがわかります。また、σの値によって、等高線の幅が変わることが分かります。
このカーネルがどのように複雑な非線形の問題に対応できるのか、具体例を用いて見ていきたいと思います。
例えば、下記図のように、フィーチャーx1, x2の空間に、ランドマークl(1), l(2), l(3)を置いたとします。また、予測のパラメータθも下記のように既に決まっていたとします。

このときに、適当な点をいくつか置いてみると、l(1)や l(2)の近くでは、f1もしくは、f2が1となり、予測結果y=1となります。また、そこから離れた点では、y=0となります。
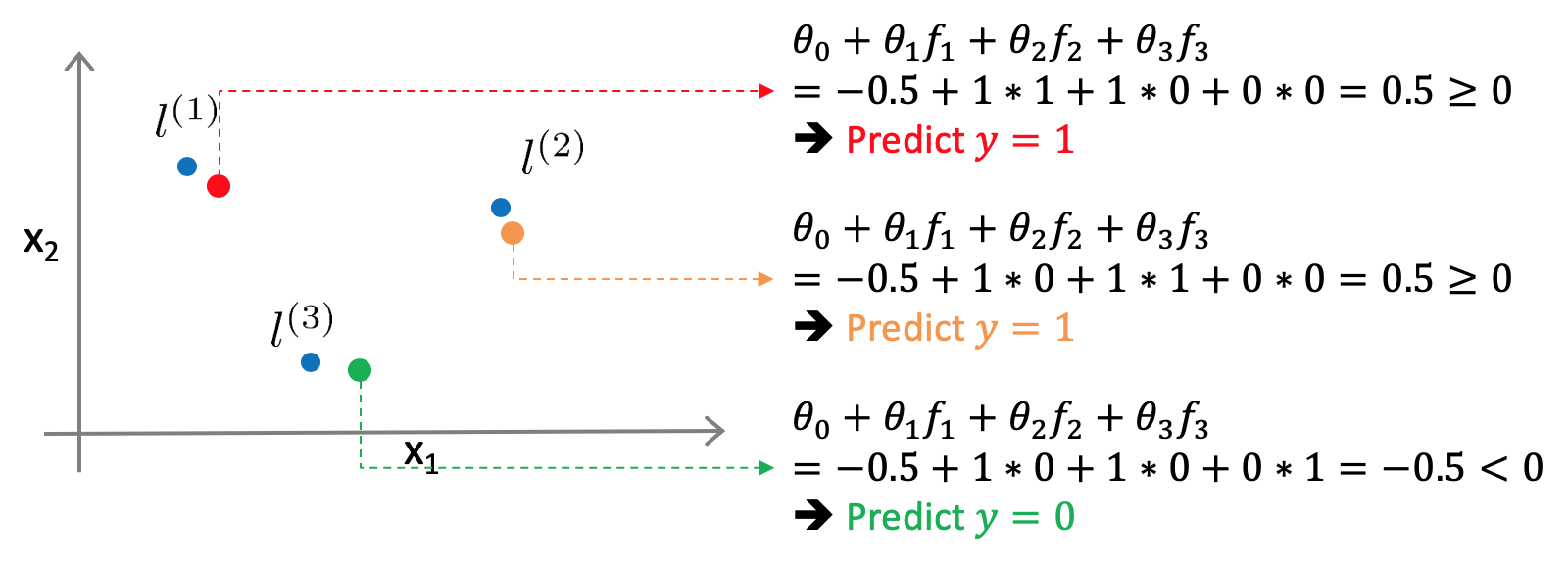
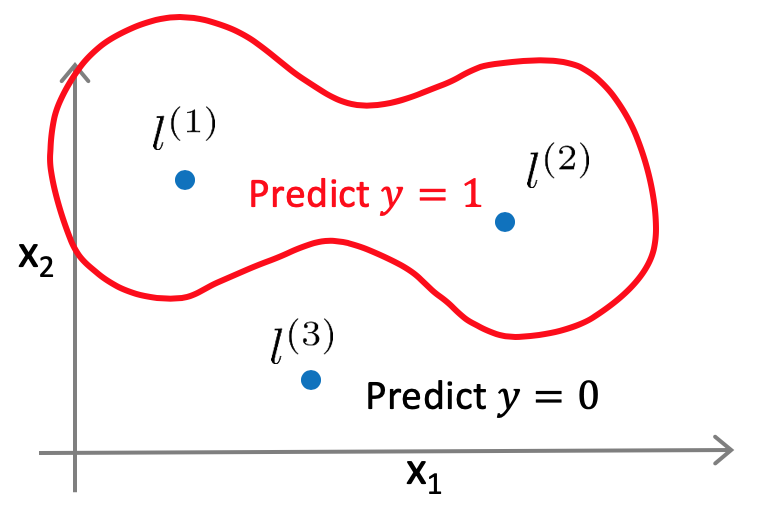
結果として、下記図のように、l(1)や l(2)の近くではy=1となるような非線形の境界線を得ることができます。ランドマークとカーネル関数を定義することで、このように、複雑で非線形な境界線を学習させることが可能となります。
次に、ランドマークlの選び方ですが、基本的には、トレーニングデータをそのまま持ち入れば良いとのことです。
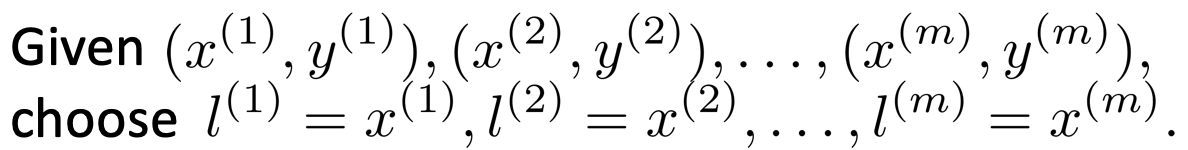
また、カーネルをSVMに適用する際、パラメータとしては、コスト関数に含まれるCと、カーネルに含まれるσ2があります。それぞれがBias、Varianceに与える影響は下記の通りです。
- C
- Large C: Lower bias, high variance
- Small C: Higher bias, low variance
- σ2
- Large σ2: Higher bias, lower variance(fの広がりが緩やかになるので)
- Small σ2: Lower bias, higher variance(fの広がりが鋭くなるので)
Using an SVM
最後に、実際にSVMを利用する際の流れについて学びます。
- SVMのライブラリは色々と存在している(liblinear、libsvm等)ので、自分でコーディングしようとせずに、それを用いる
- パラメータCを決める
- 用いるカーネルを決める
- カーネルを用いない(linear kernel / リニアカーネルを用いる)という選択もある
- 本コースで学んだ、Gaussian kernel以外にも、Polynomial kernel、String kernel、chi-square kernel、histogram intersection kernel等が存在する
- Gaussian kernelを用いる際は、パラメータσ2を決める必要がある
Multi-class classificationを行いたい場合は、多くのSVMライブラリでそれが実装されているため、それを用いれば良いとのこと。それがない場合は、分類したいクラスの数だけSVMとトレーニングし、one-vs.-allで対応すれば良いとのことです。
最後に、Logistic regressionとSVMのどちらを用いれば良いのかについてです。
- トレーニングデータ数に対し、Featureの数が十分に大きい場合は、Logistic regressionかカーネル無しのSVM(リニアカーネル)を用いる
- Featureの数が少なく、トレーニングデータ数が中くらいの場合は、ガウスカーネルのSVMを用いる
- Featureの数が少なく、トレーニングデータ数が多い場合は、新たなFeatureを追加し、Logistic regressionかカーネル無しのSVM(リニアカーネル)を用いる
- Neural Networkはどの場合でも使えるが、おそらく計算に時間がかかる
プログラミング演習
Week7のプログラミング演習では、SVMを用いて、スパムメールの分類を行います。演習の項目は、具体的には以下のものです。
- Gaussian Kernel
- Parameters (C, σ) for Dataset 3
- Email Preprocessing
- Email Feature Extraction
次回は、Week8の前半、Unsupervised Learning(教師なし学習)についてまとめます。
コース全体の目次とそのまとめ記事へのリンクは、下記の記事にまとめていますので、参照ください。
Coursera Machine Learningまとめ本記事を読んでいただきありがとうございます。
機械学習を実際に使うにあたり、Coursera MLと合わせておすすめしたい書籍を紹介します。

Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎
scikit-learnを用いた機械学習を学ぶのに最適な本です。

ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
Deep Learningと言えばこれ。TensorFlowやPyTorch等のフレームワークを用いずに、基礎の理論からDeep Learningを実装します。Week4、Week5の記事を読んで、より深く理解したいと思った人におすすめです。

Kaggleで勝つデータ分析の技術
データ分析について学び始めた人におすすめです。